프로세스
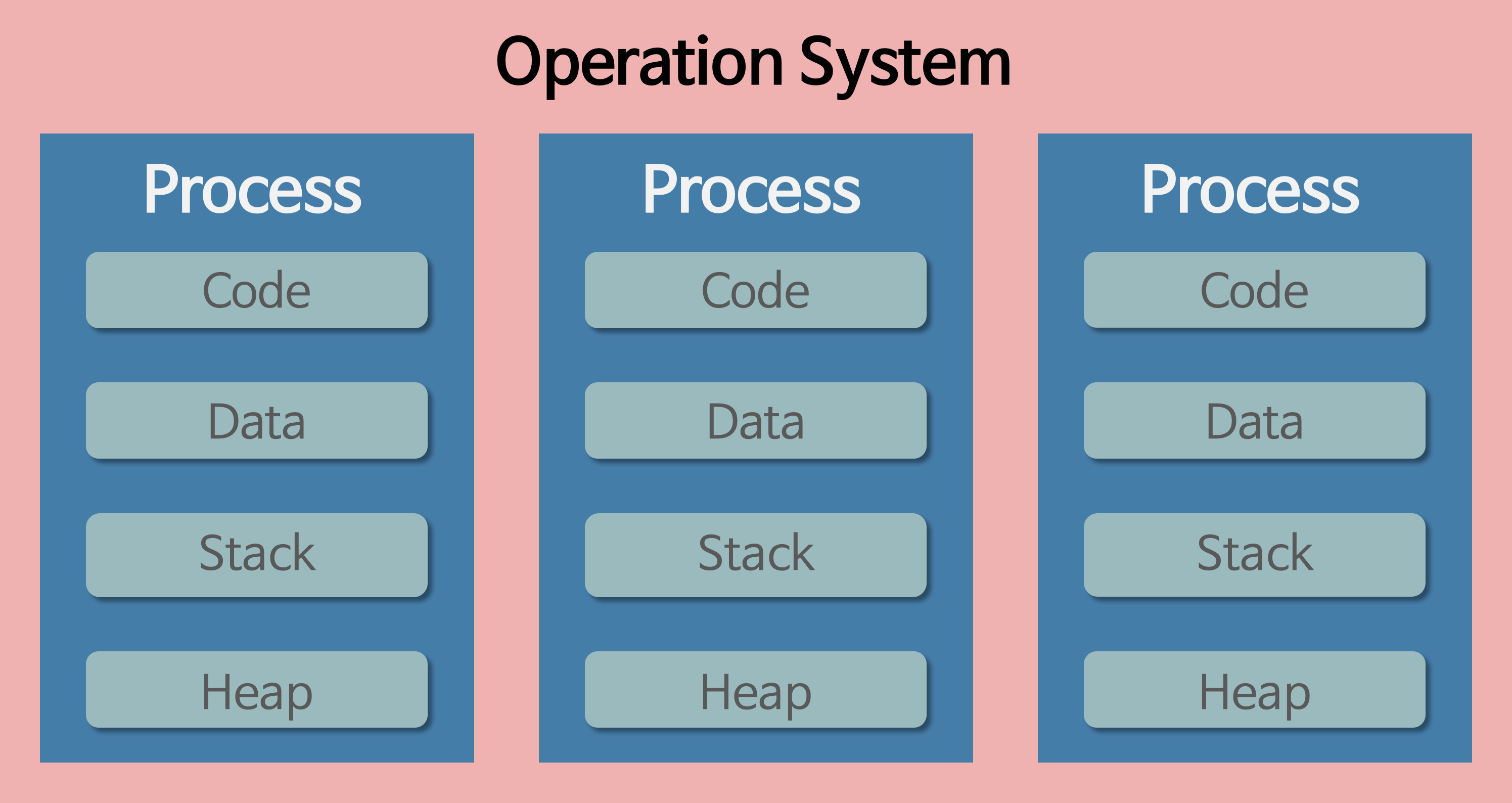
프로세스란 메모리에서 실행 중인 프로그램(program in execution)을 뜻합니다. 여기서 프로그램이란 컴퓨터에서 실행할 수 있는 파일을 통칭합니다. 카카오톡, 크롬, Visual Studio Code 등등이 전부 프로그램입니다. 이러한 HDD에 저장된 프로그램이 메모리에 올라가 실행되면 그것을 프로세스라고 부르는 것입니다. 프로그램과 프로세스의 차이는 메모리에서 실행 중인가 아니면 HDD에서 가만히 있는 중인가의 차이입니다. HDD에 있으면 프로그램이고 그게 메모리에 올라가면 프로세스입니다.
프로세스는 task, job이라고도 불리며 Code + Data + Stack + Heap 등을 갖습니다.
** Code, Data, Stack, Heap?
- Code: 프로세스의 실행 코드가 저장되는 영역입니다. 프로그램의 명령어들이 저장되어 있습니다.
- Data: 전역 변수와 정적 변수가 저장되는 영역입니다. 프로그램의 초기화된 데이터가 저장되며, 프로그램이 실행되면서 변경될 수 있습니다. 전역 변수와 정적 변수는 프로세스의 모든 부분에서 접근할 수 있습니다.
- Stack: 프로세스의 임시 데이터와 함수 호출에 사용되는 영역입니다. 지역 변수, 매개변수, 함수 호출 시 생성되는 호출 프레임 등이 저장됩니다. 스택은 후입선출(LIFO, Last-In-First-Out) 구조로 동작합니다.
- Heap: 동적으로 할당되는 메모리 영역입니다. 프로세스가 실행 중에 동적으로 할당되는 데이터, 예를 들면 동적으로 생성된 객체나 배열 등이 저장됩니다. 힙 메모리는 사용자가 직접 할당 및 해제를 제어할 수 있습니다. 일반적으로 힙은 동적 데이터 구조나 동적 메모리 할당을 위해 사용됩니다.
스레드

스레드는 설명한 프로세스 안에 있는 작업의 흐름의 단위입니다. 우리가 어떤 파일을 브라우저로 내려받는다고 생각해 봅시다. 해당 파일은 매우 커서 내려받는데 3분 정도 걸립니다. 만약 스레드가 하나라면 그 하나의 스레드는 파일을 내려받기 위해 사용되기 때문에, 우리는 인터넷 검색도 못 하고 유튜브도 못 보고 그냥 가만히 파일을 전부 내려받을 때까지 기다려야 합니다. 하지만 스레드가 두 개라면 달라집니다. 하나의 스레드는 파일을 내려받고 다른 하나의 스레드는 유튜브를 보거나 검색하거나 하는 데 사용하면 됩니다. 이렇게 하면 파일을 다운로드 받으면서 다른 일도 할 수 있게 됩니다. 물론 스레드가 동시에 두 개가 실행되는 것은 아닙니다. 하나의 시간에는 단 하나의 스레드만 동작합니다. 다만, 스레드들이 매우 빠르게 번갈아 가며 실행되기 때문에 우리가 느끼기에는 동시에 실행되는 것처럼 느껴지는 것입니다. 이러한 것 다시 말해, 엄밀하게 말하면 동시에 실행되는 것은 아니지만 동시에 실행되는 것처럼 느낄 정도로 빠르게 번갈아 가며 실행되는 것을 동시성(Concurrency)라고 합니다. 반면, 진짜 동시에 실행되는 것은 병렬성(Parallelism)이라고 합니다.
위에서 브라우저의 다운로드를 설명하며 스레드들이 매우 빠르게 번갈아 가며 실행된다고 말씀드렸습니다. 이 말은 현재 실행 중인 스레드의 실행 정보를 저장하고 다음 실행할 스레드의 실행 정보를 불러오는 작업이 필요함을 내포합니다. 왜냐하면, 어디까지 실행했었는지 저장해 놔야 그 정보를 보고 재실행할 수 있기 때문입니다. 만약 해당 정보가 없다면 다시 실행될 때 어디서부터 실행해야 하는지 모를 것입니다. 이러한 스레드의 정보들은 TCB(Thread Control Block, 스레드 제어 블록)에 저장됩니다. 이러한 TCB에는 스레드의 상태, 프로그램 카운터(Program Counter, PC)(현재 실행 중인 명령어의 주소를 가리키는 레지스터, 이것을 보고 실행할 명령어를 파악할 수 있습니다.), 스레드 우선순위 등이 저장됩니다.
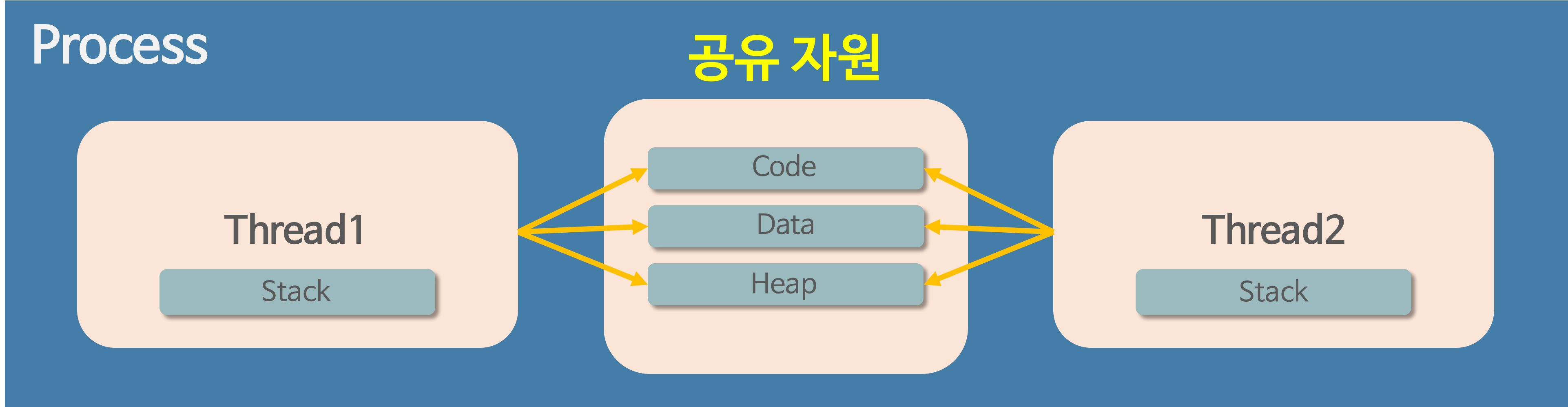
스레드는 사용 경험 향상에 있어 장점이 있을 뿐만 아니라. 컨텍스트 스위칭 시 오버헤드 감소에서도 장점이 있습니다. 스레드는 위처럼 Process의 Code, Data, Heap을 공유하고 Stack은 따로 갖고 있습니다. 코드의 호출 순서나 매개변수의 경우 공유할 필요가 없기 때문에 stack만 따로 갖는 것입니다. 따라서, 프로세스 단위로 컨텍스트 스위칭할 때는 Code, Data, Stack, Heap을 모두 바꿔야 하지만 스레드 단위 컨텍스트 스위칭의 경우 Code, Data, Heap을 공유하므로 오직 Stack만 바꾸면 됩니다. 그러므로 컨텍스트 스위칭 시 발생하는 오버헤드가 감소합니다.
** 사용 경험 향상, 컨텍스트 스위칭의 오버헤드 감소의 장점이 있지만 만능 도구는 없듯 스레드에도 분명한 문제가 존재합니다.
- 동시성 문제: 스레드는 번갈아 가며 실행되고 공유 자원에 대해 동시에 접근할 수 있습니다. 이에 따라 동시성 문제가 발생할 수 있으며 일반적으로 스레드 간의 동기화를 통해 이를 관리해야 합니다. 예를 들어, 경쟁 조건, 교착상태, 데이터 무결성 등의 문제가 발생할 수 있습니다.
- 자원 사용량: 스레드는 각각 스택 등의 자원을 소유하고 있어 메모리 사용량이 늘어납니다. 따라서 많은 스레드를 생성하면 시스템 자원을 과도하게 사용할 수 있습니다. 스레드 풀 등의 메커니즘을 사용하여 자원 사용을 최적화할 필요가 있습니다.
- 디버깅과 테스트: 스레드 간의 동시 실행은 디버깅과 테스트를 어렵게 만들 수 있습니다. 여러 스레드가 동시에 실행되기 때문에 원치 않는 상태가 발생할 수 있고, 디버깅이 어려울 수 있습니다.
👩💻 완전히 정복하는 프로세스 vs 스레드 개념
한눈에 이해하는 프로세스 & 스레드 개념 전공 지식 없이 컴퓨터의 프로그램을 이용하는데는 문제 없어 왔지만 소프트웨어를 개발하는 사람으로서 컴퓨터 실행 내부 요소를 따져보게 될때, 아
inpa.tistory.com
https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html
[OS] 프로세스와 스레드의 차이 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
https://hs-archive.tistory.com/92
운영체제 기본 6 - 프로세스 관리
http://www.kocw.net/home/search/kemView.do?kemId=978503 운영체제 운영체제의 정의 및 역할 등에 대해 알아보고, 운영체제의 주요 요소들, 즉 프로세스 관리, 주기억장치 관리, 파일 시스템 등에 대해 공부한
hs-archive.tistory.com
'운영체제' 카테고리의 다른 글
| 운영체제 기본 마지막 - 파일 시스템 (0) | 2023.01.26 |
|---|---|
| 운영체제 기본 10 - 주기억장치 관리 (0) | 2023.01.26 |
| 운영체제 기본 9 - 프로세스 동기화 (0) | 2023.01.23 |
| 운영체제 기본 8 - 프로세스 생성과 종료 (0) | 2023.01.23 |
| 운영체제 기본 6 - 프로세스 관리 (0) | 2023.01.19 |