http://www.kocw.net/home/search/kemView.do?kemId=978503
운영체제
운영체제의 정의 및 역할 등에 대해 알아보고, 운영체제의 주요 요소들, 즉 프로세스 관리, 주기억장치 관리, 파일 시스템 등에 대해 공부한다.
www.kocw.net
주기억장치 관리 (Main memory management)
이전까지 Process management(CPU scheduling, process synchronization)에 대해 배웠다. 이번 장에서는 OS의 또 다른 역할인 주기억장치 관리에 대해 알아보자. 주기억장치는 메모리를 뜻한다. 메모리는 항상 언제나 부족했었다. 그래서 주기억장치 관리의 역할은 주로 그 부족한 메모리를 어떻게 하면 최대한 효율적으로 사용할 수 있을지에 관련된 작업이다.
프로그램과 메모리 주소
프로그램이 메모리에 적재되어 실행될 때, 프로세스는 code+data+stack을 갖는다. CPU는 code에 적혀 있는 주소를 토대로 프로세스의 data에 접근할 수 있다. 문제는 프로세스가 메모리에 적재될 때 매번 다른 위치에 적재될 수 있다는 것이다. 매번 다른 메모리 위치에 적재된다는 것은 data가 저장되는 주소가 매번 달라진다는 것인데 그러면 실행할 때마다 code를 변경해야 하는 것인가? 하지만 우리는 한 번 code를 만들면 다른 요구 사항이 없다면 변경하지 않아도 된다. 어떻게 이런 일이 가능한 것일까.
우리는 MMU의 재배치 레지스터를 이용하기 때문에 매번 프로그램이 적재되는 위치가 달라지더라도 code를 변경하지 않고도 문제없이 실행할 수 있다. MMU의 relocation register는 다음과 같은 방식으로 동작한다. 우선 프로세스의 시작 메모리를 가져온다. 만약 프로세스가 500번지에서 시작한다면 relocation register는 500이 되는 것이다. 그다음 프로그램 코드를 읽다가 "0번지에 3을 저장하라"는 명령을 만나면 (0+500) 번지에 3을 저장하는 것이다. 이렇게 하면 CPU나 프로그램 제작자는 주소를 신경 쓰지 않아도 원활한 실행이 가능하게 된다. 참고로 다른 프로세스가 동작하면 OS가 알아서 MMU를 변경해 준다.(context switching) 이러한 방식으로 MMU의 relocation register를 사용하면 CPU가 요청하는 주소와 실제 데이터가 저장되어 있는 메모리의 주소가 달라지게 된다. CPU가 요청하는 주소를 논리 주소(logical address)라 하고 MMU를 통과하여 만들어지는 주소를 물리 주소(physical address)라 한다.
메모리 낭비 방지
OS는 항상 부족한 자원인 메모리의 낭비를 방지하기 위해 동적 적재(dynamic loading), 동적 연결(dynamic linking), 스와핑(swapping)을 사용한다. 동적 적재와 동적 연결 스와핑이 어떤 방식으로 작동하길래 메모리 낭비를 방지하는지 각각의 방법에 대해 알아보자.
Dynamic loading
- 프로그램 실행에 반드시 필요한 루틴/데이터만 적재하는 방법이다.
- 모든 루틴/데이터가 전부 사용되는 것은 아니다. (오류 처리 루틴은 오류가 일어날 때만 사용되고 배열의 크기를 1000으로 선언해 놓았다고 해서 1000만큼을 다 쓴다는 것은 아님. 자바의 경우 모든 클래스가 다 사용되는 것은 아님.)
- 따라서 전부를 올리지 말고 필요하면 그때 해당 부분을 메모리에 올리자!
- 반대의 방법으로는 static loading(정적 적재)이 있다. 정적 적재는 그냥 다 올려버려~ 하는 것이다. 보통 OS는 Dynamic loading을 사용한다.
Dynamic linking
- 여러 프로그램이 공통적으로 사용하는 library를 메모리에 하나만 적재하는 방법이다.
- 라이브러리 루틴 연결을 실행 시까지 미룬다.
- 공통 library routine을 메모리에 중복으로 올리는 것은 낭비이다. 오직 하나의 라이브러리 루틴만 메모리에 적재하고, 해당 라이브러리를 사용하는 APP 실행 시 이 루틴과 연결(Link)된다.
- Linux는 공유 라이브러리(shared library)라 하고 windows는 동적 연결 라이브러리(Dynamic linking libarary)라 한다. 윈도우에서 *.DLL 파일이 바로 이러한 동적 연결 라이브러리의 파일 확장자 이름이다.
- 반대의 방법으로는 Static linking이 있다.
- 예를 들어 A.c와 B.c 파일 두 개가 있다고 생각해 보자. A.c도 printf() 함수를 사용하고 B.c도 printf() 함수를 사용한다. 만약 이 두 파일을 각각 실행파일로 만든다면 A.exe에 printf() 함수가 기계어 코드로 포함되게 되고 B.exe 파일에도 printf() 함수가 기계어 코드로 들어가게 될 것이다. 이것을 정적 연결(Static linking)이라 한다. 이 두 실행 파일을 실행하면 같은 함수를 지칭하는, printf() 함수를 기계어로 번역한 코드가 중복되어 memory에 적재되는 것이다. 이는 분명한 메모리 낭비이다. 동적 연결은 이러한 문제를 해결한다. 동적 연결 방식을 사용하면 printf() 함수가 호출되었을 때 library와 link 되어 함수를 사용할 수 있게 된다. 예전의 OS는 정적 연결을 했으나 최신 운영 체제는 실행될 때 그게 없으면 hdd에서 printf() 모듈이 로드되는 동적 링킹 방식을 사용한다.

Swapping
- 메모리에 적재되어 있으나 현재 사용되고 있지 않은 프로세스를 backing store(=swap device)로 몰아내는 방법이다.
- backing store는 hdd의 일부 공간을 할당받아 만든다.
- 메모리에 적재되어 있는 것을 쫓아낼 때 swap-out이라 하고 다시 들여보낼 때를 swap-in이라 한다.
- 프로세스의 크기가 클수록 backing store 입출력에 따른 부담이 크다.(프로세스의 크기가 클수록 느리다.)
- OS는 메모리에 올라와 있으면서 일정 시간 동안 사용되지 않은 프로세스를 감지하여 hdd의 특정 부분(backing store)으로 쫓아낸다. 이때 backing store에 저장된 정보(code+data+stack)를 이미지라 한다. 서버 컴퓨터 같은 큰 컴퓨터는 백킹 스토어를 위한 hdd를 따로 두고 프로그램들을 위한(File system) hdd를 따로 두기도 한다. 하지만 개인 PC나 스마트폰은 하나의 hdd를 나누어 사용한다. backing store의 크기는 대량 메인 메모리의 크기만큼 할당하면 된다. 메인 메모리에 올려져 있는 프로세스들이 쫓겨나는 것이기 때문이다. 아래 그림에서 swap-Out을 하면 p1 자리가 비게 되고 그 자리에 다른 프로세스가 들아갈 수 있게 된다. 따라서 swap-in 될 때 무조건 자신의 예전 자리로 돌아가는 것이 아니라 빈자리로 들어가게 된다. 이때 MMU의 base, limit, relocation 값이 변경된다. hdd의 입출력 속도는 메모리에 비해 매우 느리므로 속도면에서 굉장한 손해이다.

연속 메모리 할당(contiguous memory allocation)
연속 메모리 할당이란 프로그램에게 연속된 메모리를 할당해 주는 방식을 뜻한다. 여러 프로그램이 메모리에 적재되는 다중 프로그래밍 환경에서 부팅 직후 메모리 상태는 OS + big single hole로 이루어져 있지만 프로세스 생성 & 종료의 반복을 거치면 scattered(뿔뿔이 흩어진) holes가 생겨난다. 이렇게 scattered holes가 생기는 과정을 메모리 단편화라 하며 메모리 단편화가 발생하면 연속 메모리 할당 방식의 경우 충분한 메모리 공간이 있음에도 프로그램을 메모리에 적재시키지 못하는 문제가 발생하게 된다. 다음 설명을 보며 이를 이해해 보자.
아래는 한 번의 부팅과 여러 번의 프로세스 생성 & 종료를 반복한 뒤의 메모리 상태를 나타낸 그림이다.

저렇게 scattered holes가 생기면 아래와 같은 문제가 발생할 수 있다. 아래 그림은 130KB의 프로그램을 메모리에 적재하려 할 때 메모리에 총 170KB만큼의 빈자리가 있는데 메모리의 빈 공간들이 불연속적으로 존재하기 때문에 연속 메모리 할당 방식으로는 130KB의 프로그램을 적재시킬 수 없는 상황을 나타낸 것이다. 충분한 자리가 있음에도 불연속적으로 hole이 있어서 프로그램을 적재시키지 못하는 이러한 상황을 외부 단편화라고 한다.

위와 같은 문제가 발생하는 이유는 첫째로 불연속적인 구멍들이 생기기 때문이고 둘째로는 연속 메모리 할당 방식을 사용하기 때문이다. 따라서 문제를 해결하기 위해서는 불연속적인 구멍들이 많이 생기지 않도록 하는 방법과 연속 메모리 할당 방식 말고 불연속 메모리 할당 방식을 사용하면 된다. 우리는 우선 불연속적인 구멍들이 많이 생기지 않도록 하는 방법에 대해 배워보자. 이 방법에는 First-fit, Best-fit, Worst-fit이 있다.
First-fit
- 위에서부터 아래로 혹은 아래서부터 위로 등의 순서를 가지고 메모리의 hole을 탐색한다. 적재 가능할 만큼의 hole을 찾았다면 바로 그 자리에 프로그램을 연속 메모리 할당한다.
Best-fit
- 프로그램의 크기와 가장 비슷한 hole을 찾아서 그곳에 적재한다.
Worst-fit
- 프로그램의 크기와 가장 차이가 많이 나는 hole을 찾아서 그곳에 적재한다.
아래와 같은 메모리 상황에서 212, 417, 112, 426 짜리 프로그램을 메모리에 적재시킬 때를 가정하여 각각의 방법을 적용시켜 보자.
- first-fit을 사용하면 212가 500KB짜리 hole에 들어가고 hole은 183KB가 된다. 417이 600KB짜리 hole에 들어가고 hole은 183KB가 된다. 112가 288KB에 들어가고 hole은 176KB가 된다. 마지막으로 426은 들어갈 수 있는 hole이 없다. (외부 단편화 발생!)
- best-fit을 사용하면 212는 가장 비슷한 300KB hole에 들어가고 hole은 88KB가 된다. 417은 500KB에 들어가고 hole은 83KB가 된다. 112는 200KB에 들어가고 hole은 88KB가 된다. 마지막으로 426은 600KB에 들어가고 hole은 174KB가 된다.
- worst-fit을 사용하면 212가 600KB에 들어가고 hole이 388KB가 된다. 417은 500KB에 들어가고 hole은 83KB가 된다. 112는 388KB에 들어가고 hole은 276KB가 된다. 마지막으로 426은 적재할 수 없다. (외부 단편화 발생!)
할당 방식에 대한 성능을 비교해 보자면 속도는 first-fit이 가장 빠르고 메모리 이용률은 first-fit과 best-fit이 가장 좋다. 하지만 어느 방법을 사용하더라도 외부 단편화가 일어나고 외부 단편화로 인한 메모리 낭비는 약 1/3 수준이다. 다시 말해, 900KB짜리 메모리를 사용한다면 약 300KB를 외부 단편화 때문에 사용하지 못하는 것이나 다름없다. 이를 해결하기 위해 압축(compaction)을 할 수도 있지만 압축은 최적 알고리즘이 없고 고부담이기 때문에 보통 위에서 말한 비연속 메모리 할당 방식(페이징)을 사용한다. 참고로 압축이란 단편화되어 나누어져 있는 hole들을 하나의 hole로 합치는 것을 뜻한다. 압축은 합친 hole을 어디에다 둘지 프로세스들은 어디로 옮길지 등 생각해야 할 것이 많다.
페이징(paging)
페이징이란 프로그램을 일정한 단위로 나눈 뒤 마찬가지로 일정한 단위로 나눈 hole에 넣는 방식을 뜻한다. 이렇게 프로그램을 일정한 단위로 나누어 일정한 단위로 나뉜 hole에 넣게 되면 프로세스가 연속되지 않고 나누어져 적재가 되는데 그러면 CPU가 address를 통해 프로세스의 data에 접근할 때 문제가 생긴다. 이를 해결하기 위해 MMU에 relocation register를 페이징 한 개수만큼 만든다. 일정한 단위로 나눈 프로세스의 조각을 page라 하고 일정한 단위로 나눈 메모리의 조각을 frame이라 한다. 다시 말해 process는 page의 집합이 되고 메모리는 frame의 집합이 되는 것이다. 여러 page를 여러 frame에 할당할 때 MMU 내의 relocation register를 여러 개 두게 되므로 이때의 MMU를 페이지 테이블이라 부른다.
정리하자면 다음과 같다. 프로그램도 hole도 똑같이 10등분 했을 때 10등분 된 하나의 hole을 "frame"이라 하며 10등분 된 하나의 program 조각을 "page"라 한다. 각각의 page는 각각의 frame에 딱 맞게 들어가야 하므로 page와 frame의 크기는 같아야 한다. 또한 CPU가 여러 페이지들을 하나의 프로세스로 인식하게끔 만들어야 하는데 이를 위해 MMU에 여러 개의 relocation register를 둔다. 이렇게 여러 개의 relocation register를 갖는 MMU를 Page table이라 한다. 이러한 페이징 방법을 사용함으로써 외부 단편화로 인한 메모리 낭비 문제를 해결할 수 있다.
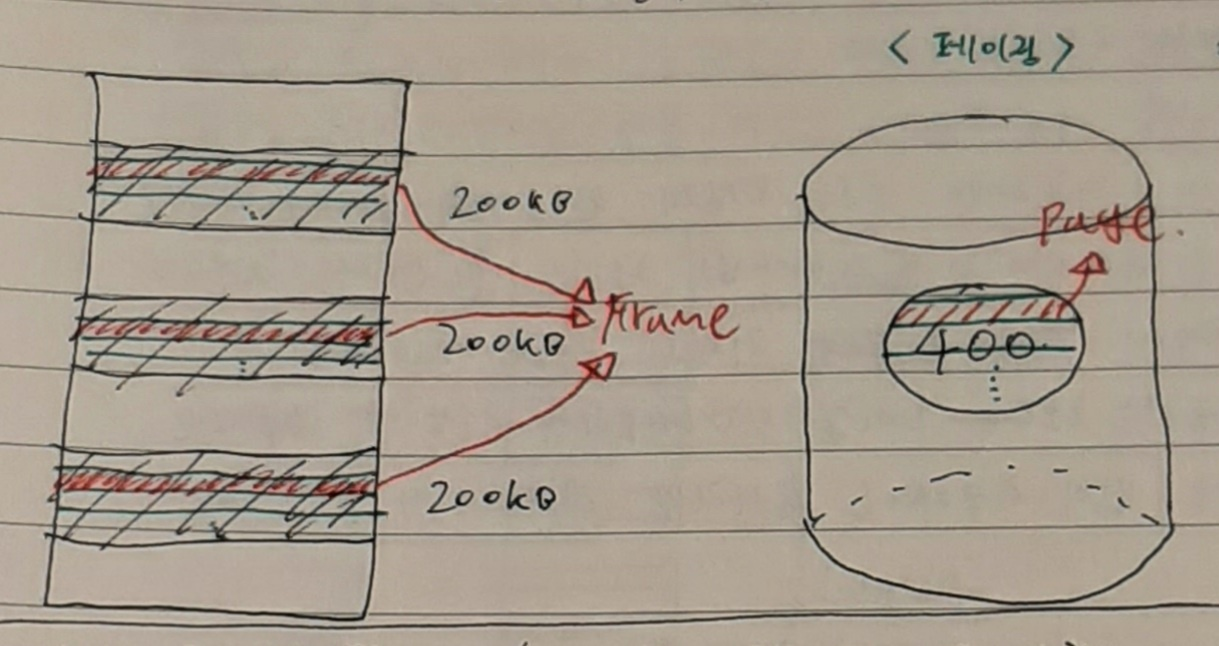
프로세스 크기가 페이지 크기의 배수가 아니면 마지막 페이지는 한 프레임을 다 채울 수 없다. 예를 들어 프로그램이 121KB이고 page size가 40KB라면 총 4개의 frame를 할당받아야 한다. frame 4개의 총크기는 160KB이고 프로그램의 크기는 121KB이므로 총 39KB가 낭비된다. 이렇게 발생하는 단편을 내부 단편화라 부른다. 따라서 연속 메모리 할당을 하면 외부 단편화가 발생하고 페이징을 사용하면 내부 단편화가 발생하는 것이다. 하지만 내부 단편화는 외부 단편화보다 그 크기가 작으므로 페이징을 사용하는 것이 더 좋다.
** page table을 이용한 주소 변환 과정
논리 주소(Logical address)는 CPU가 내는 전체 m 비트의 2진수 값이다. 하위 n 비트는 오프셋 또는 변이(displacement)라 부른다. 상위 m-n(P라고 부름) 비트는 페이지 인덱스 값으로 이 인덱스를 통해 page table에서 원하는 값을 얻고 그 값을 P대신에 기입하면 최종적으로 물리 주소를 얻을 수 있다. n의 크기는 page의 사이즈에 달려 있다. page size가 2^4이면 n = 4 bit이고 page size = 1KB이면 1KB = 2^10이므로 n = 10 bit가 된다. 예를 들어 page size가 1KB이고 page table이 [1,2,3,4,5,6,7]일 때 CPU가 1011 1011 1000번지에 있는 주소를 가져오라 명령하면 앞의 두 비트 10이 P가 되고 그 뒤의 11 10 11 1000은 D가 된다. D는 가만히 내버려 두고 P만 확인하면 된다. P를 10진수로 변환하면 2가 되고 page table의 인덱스 2에 해당되는 값은 3이다. 3은 2진수로 변환하면 11이 되므로 최종적으로 물리 주소는 11에다가 D를 붙인 값인 1111 1011 1000이 되는 것이다.

** page table 만들기
page table은 CPU 내부에 CPU 레지스터로 넣을 수도 있고 메모리 내부에 넣을 수도 있고 TLB(Translation Look-aside Buffer)로 만들 수도 있다. CPU 내부 레지스터에 저장하면 속도는 가장 빠르겠지만 많이 저장하질 못하고 메모리에 넣으면 CPU 안에 있는 레지스터보다 계산 속도가 매우 느리므로 속도가 느려지겠지만 저장은 많이 할 수 있을 것이다. TLB는 바로 이것들의 중간으로서 메모리보단 빠르면서 CPU 레지스터보단 많이 저장하는 방법이다. TLB란 속도가 빠른 SRAM에 저장된 page table을 뜻한다.
** TBL 사용 시 유효 메모리 접근 시간 구해보기
Tm = 100ns (메모리에서 데이터를 찾는 시간 100ns)
Tb = 20ns (TLB에서 주소 변환을 하는 데 걸리는 시간 20ns)
hit ratio = 80% (CPU가 보낸 논리 주소를 물리 주소로 변환했을 때 해당 page index가 TLB에 있을 확률. SRAM의 크기가 모든 page index를 담기에는 작기 때문에 TLB에 모든 인덱스를 기록하진 않는다. TLB에 기입되지 않은 page table은 메모리에 저장된다.)
Effective memory access time
= page_index가 TLB에 있을 확률 * (Tb + Tm) + page_index가 TLB에 있지 않을 확률 * (Tb + Tm + Tm) page_index가 TLB에 있지 않을 확률에 Tm을 두 번 더하는 이유는 (메모리에 있는 page table에서 index에 해당되는 주소 가져오기 + 주소에 해당되는 메모리에 있는 실제 데이터 가져오기) 메모리에서 총 두 번의 작업을 해야 하기 때문이다.
= h(Tb + Tm) + (1-h)(Tb+Tm+Tm)
= 0.8*120 + 0.2*220
= 140ns
만약 페이징을 하지 않았다면 page table 참조 없이 원래 메모리만 읽으면 되므로 100ns일 텐데 외부 단편화를 방지하기 위해 페이징 작업을 하니 TLB를 만들어야 했고 TLB를 만드니 메모리 접근 시간이 140ns로 40%나 증가했다. 하지만 이렇게 해야 1/3만큼의 메모리 손실을 가져오는 외부 단편화를 막을 수 있고 또, 실제 hit ratio는 지역성의 원리에 의해 95% 이상이므로 여러모로 paging 기법을 사용하는 것이 좋다.
** 페이징과 page table의 최종 정리는 다음과 같다.
process는 한 덩이 그대로 메모리에 적재되는 것이 아닌 여러 조각으로 나누어져 메모리에 올라가게 된다. 이 조각의 크기를 page size라 하며 프로그램을 나눈 각각의 조각을 page라 한다. 메모리는 page size와 같은 크기의 frame 조각들로 이루어지게 된다. 여러 조각으로 나누어진 프로그램을 메모리에 적재하는 것을 Loading이라 한다. 한편 CPU와 메모리 사이 page table이 있는데, 이는 나누어진 프로세스의 조각들을 CPU가 인식할 때 하나의 연속된 프로세스로 인식할 수 있도록 여러 개의 relocation register로 이루어진 MMU이다. page table은 캐시와 비슷하게 SRAM에 있으며 모든 relocation register가 page table에 있지는 않고 SRAM에 그것들을 전부 넣기에는 용량이 부족하니 일부는 메모리 안에 있는 OS에 저장한다. CPU가 요청하는 주소를 논리 주소라 하며 page table의 변환 작업을 거쳐 물리 주소가 된다.
페이징과 보호: 해킹 등을 방지
모든 주소는 page table을 경유하므로 page table entry마다 r, w, x 비트(r = read, w = write, x = execute)를 부여하여 해당 페이지에 대한 접근 제어를 할 수 있다. 예를 들어 아래와 같은 상황에서 CPU는 7번 frame에 해당하는 정보를 재작성(write)하거나 실행(execute) 할 수 없다. 왜냐하면 page table의 7번 frame의 w와 x 비트가 0 이기 때문이다. 만약 재작성 혹은 실행을 하려 하면 page table이 허용하지 않은 동작임을 인지하고 CPU에게 interrupt 신호를 보낼 것이다. 페이징을 사용하여 이러한 방식을 채택하면 어려운 점이 페이징은 논리적으로 프로그램을 나눈 것이 아니라 그냥 일정하게 나눈 것이기 때문에 r, w, x 부분이 딱 떨어지진 않을 수도 있다는 점이다. 이를테면 하나의 page에서 일부는 r을 허용하고 싶고 또 다른 일부는 r을 허용하고 싶지 않다면 어찌할 방법이 없다.

페이징과 공유: 메모리 낭비 방지
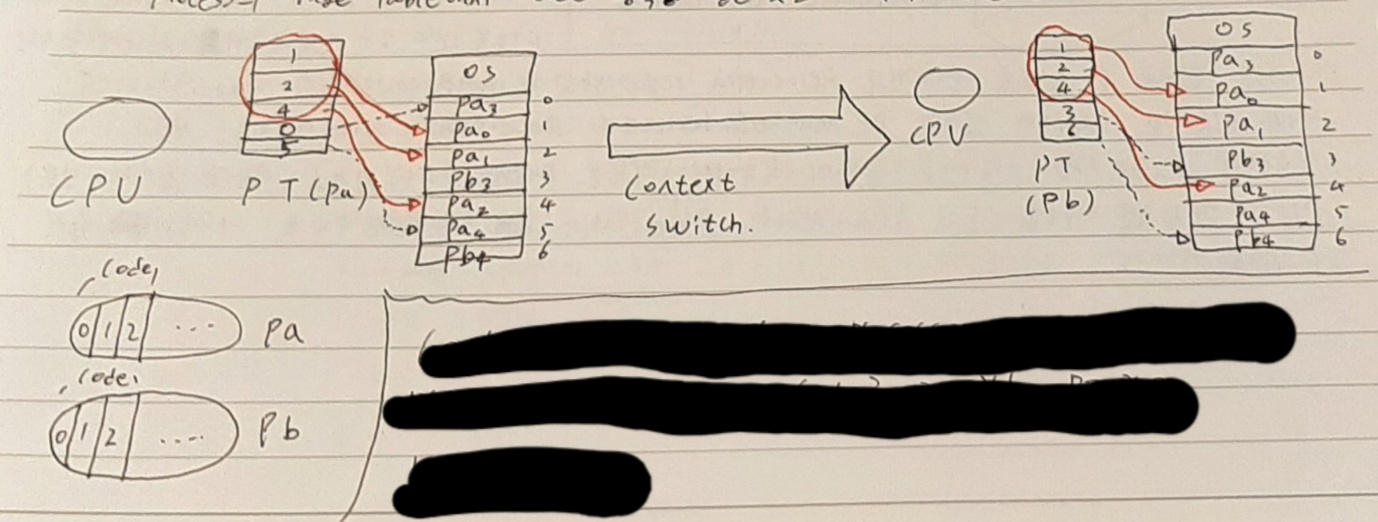
같은 프로그램을 쓰는 복수 개의 프로세스가 있다면 code+data+stack 중 code 부분이 중복되므로 code를 공유하여 사용할 수 있다. 예를 들어 워드 프로세서를 세 개 띄웠다고 생각해 보자 data, stack은 달라야 하겠지만 code 부분은 어차피 같을 것이다. 따라서 code를 공유하여 메모리 낭비를 방지하고자 하는 것이다. 단, 코드 공유가 가능하려면 코드가 실행 중 변하지 않아야 한다. 이러한 코드를 non-self modifying code(스스로 바뀌지 않는 코드) 혹은 reentrant code(다시 들어갈 수 있는 코드 = 재진입할 수 있는 코드) 혹은 pure code(순수 코드)라 한다. 이는 프로세스의 page table에서 code 영역을 같은 곳을 가리키게 하는 방법으로 구현할 수 있다. 아래 그림은 pa와 pb가 동일한 code 부분(0, 1, 2)을 공유할 때 각각의 page table이 동일한 code 주소를 가리키는 것을 나타낸다. 이것도 보호에서 본 것과 마찬가지로 페이징은 의미 단위로 나눈 것이 아니라 일정한 크기로 나눈 것이기 때문에 code 부분이 딱 나눠 떨어지지 않을 수 있다. 예를 들어. 3번 의 20%까지 공통된 code를 갖고 있다면 어떻게 해야 할까. 페이징만을 사용하면 이러한 문제가 있다.
세그먼테이션(segmentation)
프로세스를 논리적 내용으로 잘라서 메모리에 배치하는 것을 말한다. 페이징은 논리적인 내용 말고 그냥 일정한 크기로 잘랐지만(e.g. 10kb 단위로 자르기) 세그먼테이션은 논리적 내용을 기준으로 자른다.(e.g. code, stack, data로 자르기) 세그먼테이션은 프로그램을 논리적 내용을 기준으로 자르기 때문에 위에서 본 페이징을 사용했을 때 발생하는 문제들을 해결할 수 있다. 세그먼테이션에서 프로그램을 나눈 각각의 조각을 지칭하는 단어는 세그먼트이다. 세그먼테이션도 페이징과 마찬가지로 page table이 존재한다 단, 세그먼테이션의 테이블은 segment table이라 한다. 페이징의 경우 메모리와 프로그램을 일정한 크기로 나누어 변위의 크기가 frame의 크기를 넘을 수 없었는데, segmentation은 일정한 크기가 아니므로 잘못하면 할당받은 주소의 크기를 넘어설 수도 있다. 이를 감지하기 위해 segment table은 limit 값을 가지며 요청 주소와 limit 값을 비교해 침범을 감지하고 침범 발생 시 인터럽트를 발생시킨다. 이를테면, 아래 그림에서 논리 주소 (2, 100)이 3100을 의미한다고 할 때 (0, 600)은 1100을 의미하므로 base+limit의 값인 1000을 넘으므로 인터럽트를 발생시킬 것이다.

세그먼테이션의 보호와 공유
paging을 사용하면 논리적 의미에 따라 나누지 않고 그냥 일정 크기에 따라 나누기 때문에 code, data, stack이 깔끔하게 나눠지지 않고 code에 data가 좀 들어가고 data에 stack이 좀 들어갈 수 있다. 따라서 paging을 사용할 경우 보호와 공유가 어렵게 된다. 다시 말해 섹션으로 딱 나눠서 역할을 주고 싶은데 페이징은 애초에 그렇게 나눈 것이 아니기 때문에 문제가 발생하는 것이다. 반대로 세그먼테이션의 경우 나누는 기준이 '논리적 의미' 이므로 역할에 따른 권한 부여가 페이징에 비해 손쉽다는 장점이 있다.
세그먼테이션의 외부 단편화
세그먼트의 크기는 고정이 아니라 가변적이다. 따라서 연속 메모리 할당할 때 나타났던 문제가 다시금 나타나게 된다. 프로세스를 잘라서 적재시키는 것은 외부 단편화 문제를 해결하기 위함인데 세그먼테이션은 보호와 공유의 측면에서 이점이 있지만 정작 해결해야 하는 외부 단편화 문제를 해결해주지 못한다. 어떻게 두 방법의 장점만을 취사선택할 순 없을까...
세그먼테이션 + 페이징
세그먼테이션은 보호와 공유 면에서 효과적이고, 페이징은 외부 단편화 문제를 해결한다. 그러므로 세그먼트를 페이징하자! (paged segmentation) 실제로 Intel 80X86이 이 방식을 채택했다. paged segmentation을 사용하면 보호와 공유도 효과적이면서 외부 단편화 문제도 해결하지만, CPU가 보내는 주소를 두 번 변환해야 하므로 시간 소요 측면에서 좋지 않다.(tradeoff가 있음)

가상 메모리(virtual memory)
물리 메모리 크기 한계를 극복하기 위한 방법이다. 물리 메모리보다 큰 프로세스를 실행할 수 있다. 예를 들어, 100MB 메인 메모리에서 200MB 프로세스를 실행할 수 있도록 하는 방법이다. 프로세스 이미지(PCB에 정의된 프로그램과 데이터, 스택, 속성들의 집합)를 모두 메모리에 올릴 필요는 없다는 아이디어로부터 시작된 방법이다. 동적 적재와 비슷한 개념이다. 현재 우리가 사용하는 모든 컴퓨터는 가상 메모리를 사용한다.
Demand paging(요구 페이징)
요구 페이징이란 CPU가 요청할 때 비로소 페이지를 메모리에 올리는 것을 의미한다. 메모리에 올라와 있지 않은 프로세스의 이미지는 backing store에 저장되어 있다. page table에 valid 비트를 추가하여 현재 요구하는 페이지가 메모리에 올라가 있는지 아니면 backing store에 있는지를 확인할 수 있다. 과정을 예로 들면 다음과 같다.
일단 필수적인 page만 메모리에 적재를 하고 메모리에 적재되어 있는 것은 valid bit 1 적재되어 있지 않은 것은 valid bit 0으로 기입한다. ①CPU가 메모리에 올라와 있지 않은 page를 요구하면 ②page table은 interrupt를 전달하고 ③CPU는 OS의 page fault handling routine을 실행한다. ④그러면 backing store에 있는 page가 메모리에 적재되고 ⑤이제 해당 페이지 정보가 page table에 업데이트된다. ⑥이제 해당 주소의 작업을 실행할 수 있다.
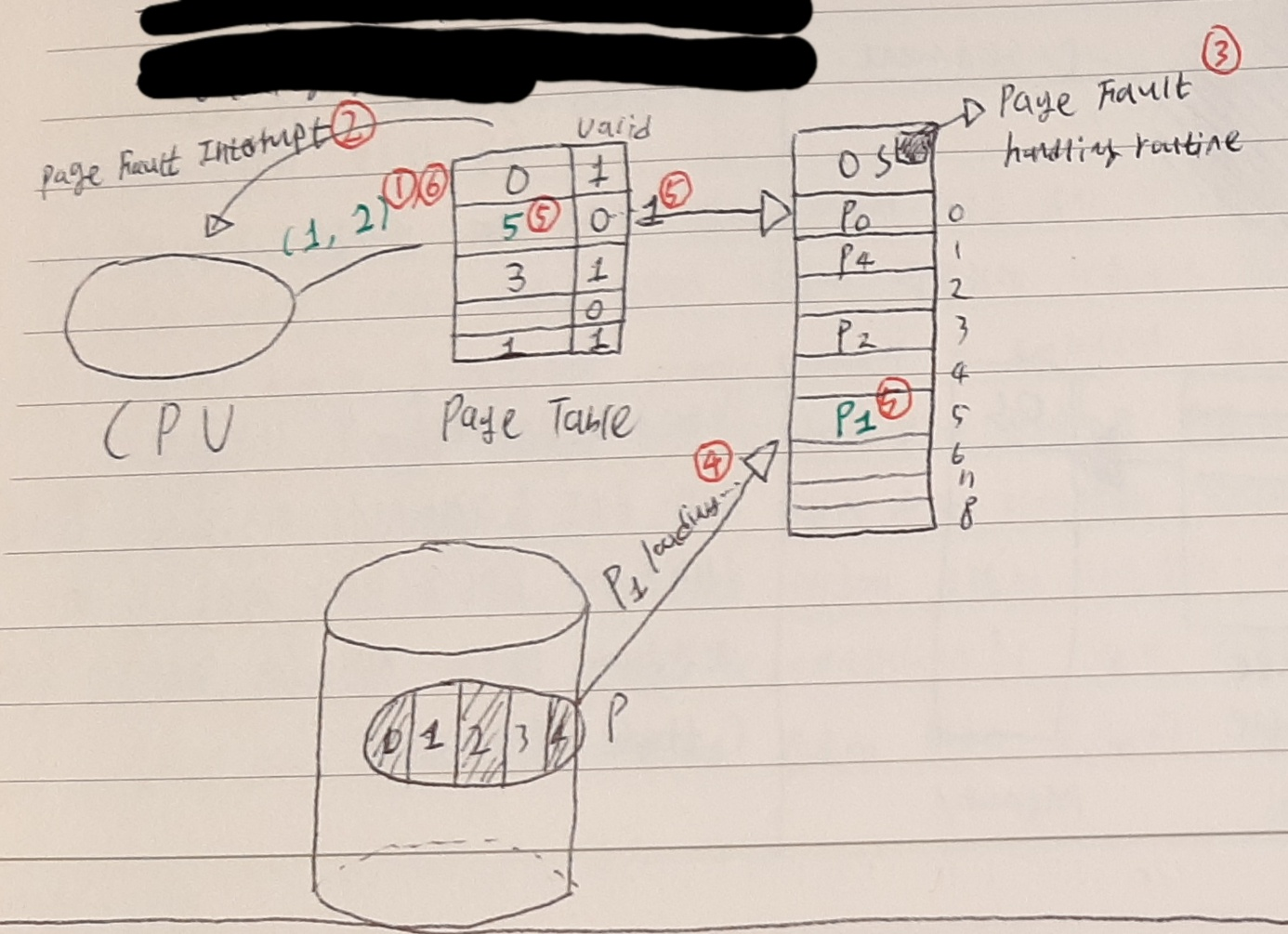
page fault(= 페이지 결함, 페이지 부재)
접근하려는 page가 메모리에 없을 때를 의미한다. page fault 발생 시 인터럽트를 발생시켜 backing store에 잠들어있는 페이지를 적재시켜야 한다.
** pure demand paging vs prepaging
pure demand paging은 진짜 아무것도 안 적재 시키고 모든 것을 page fault 해서 적재하는 방법이다. 메모리 절약이 많이 되지만 당연히 소요 시간이 많이 걸린다. 그 반대로 prepaging이란 당장 필요하지 않더라도 필요하다 싶은 page를 미리 적재하는 방식이다. 메모리 절약은 조금 덜 되겠지만 시간을 더 아낄 수 있다.
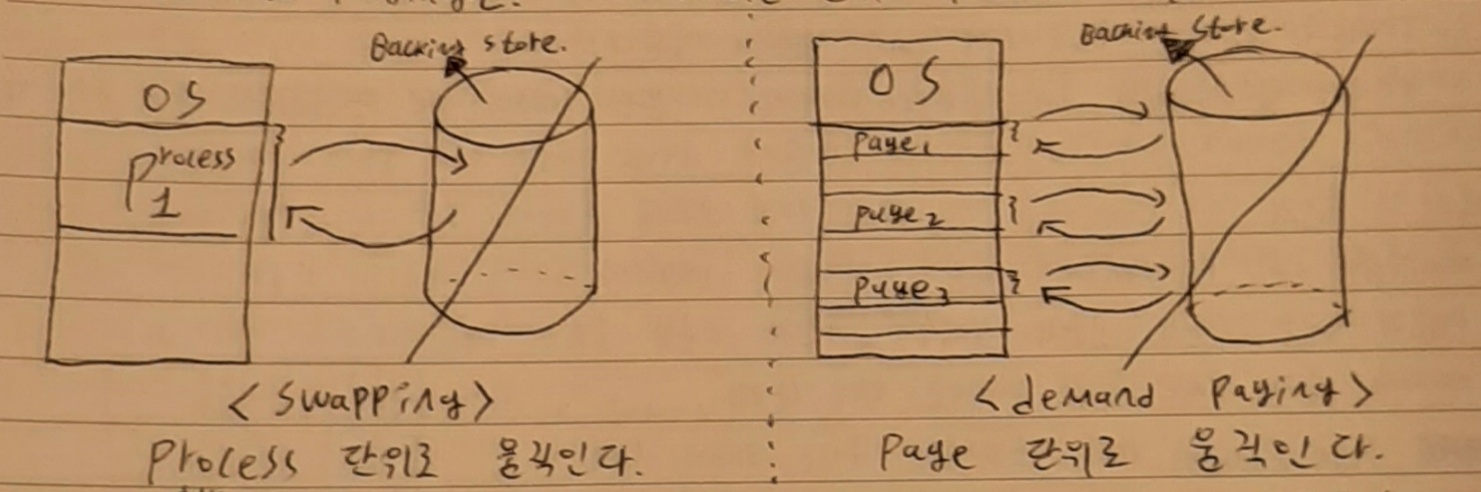
** swapping vs demand paging
swapping은 process 전체를 backing store로 몰아냈다가(swap out) 나중에 다시 프로세스 전체를 메모리에 적재시키는(swap in) 방법을 뜻한다. demand paging은 in-out 되는 단위가 process가 아니라 page 단위이다.
요구 페이징의 유효 접근 시간
p: page fault rate
Tm: 메모리에서 작업하는 데 걸리는 시간
Tp: page fault 발생 시 Interrupt 발생시키고 hdd에서 해당 page를 memory에 올리는 시간. hdd에서의 작업은 실제 물리적인 헤더를 움직이는 시간이 걸리기 때문에 interrupt를 발생시키는 것이나 메모리에서 page를 찾는 것에 비해면 매우 느린 작업이다.
예를 들어, Tm = 200 nsec이고 Tp = 8 msec일 때 Effective Access Time은 다음과 같다.
= (1 - p)*Tm + p*Tp
= (1 - p)*200 + p*8,000,000
= 200 + 7,999,800p
만약 p = 1/100이라면 접근 시간은 8,200 nsec으로 요구 페이징 없이 그냥 사용했을 때 보다 약 40배가 느리고 p = 1/399,990 접근 시간은 220 nsec으로 요구 페이징 없이 그냥 사용했을 때 보다 약 10% 느리다. 따라서 p가 매우 낮아야 좀 쓸만하고 1/1000 정도로는 매우 부족하다. 다행히 지역성의 원리가 있기 때문에 p는 요구 페이징을 쓸만할 정도로 낮다.
** hdd의 seek time, rotation delay, transfer time
디스크의 쓰기와 읽기는 헤더에 붙어있는 전기 코일에 전기를 흘려 disk에 N극 S극 정보를 저장하고 읽을 때에는 디스크를 빠른 속도로 회전시켜 N극 S극이 coil을 지나면서 전기를 유도하는 방식으로 이루어진다. 이 디스크를 읽는 데 걸리는 시간은 무엇일까. 아래 그림을 토대로 이해해 보자. 우리가 현재 읽고 싶은 부분이 아래 그림에서의 초록색으로 칠한 네모 부분이라면 저 라인까지 헤더가 한 칸 전진해야 한다. 이렇게 디스크 헤더를 우리가 원하는 트랙으로 옮기는 데 걸리는 시간을 seek time(탐색 시간)이라 한다. 그다음 저 네모를 읽으려면 저 부분이 header의 coil 밑으로 와야 한다. 저 네모 부분이 헤더 밑까지 오는 데 걸리는 시간을 rotation delay(회전 지연 시간)이라 한다. 마지막으로 네모 부분을 처음부터 끝까지 전기 신호로 읽는 데 걸리는 시간을 transfer time이라 한다. 이 세 가지 시간이 하드디스크가 정보를 읽는 데 걸리는 시간의 전부이다. 따라서 하드 디스크의 정보를 읽는 데 걸리는 시간 = seek time + rotation delay + transfer time이다. 이중 header가 원하는 track까지 움직이는 데 걸리는 시간인 seek time이 가장 오래 걸린다. 하드디스크는 1분에 약 7200회 회전하므로 rotation delay나 transfer time은 별로 오래 걸리지 않는다. 따라서 위 요구 페이징 유효 접근 시간의 예시에서 나온 Tp = 8 msec의 대부분은 seek time 소요 시간이다.

** 지역성의 원리(principle of locality)
CPU가 참조하는 주소는 어떤 지역(local)에 모여 있다. 메모리 접근은 시간적으로도 지역성을 가지고 공간적으로도 지역성을 갖는다. 시간적 지역성이란 한 번 읽은 주소는 좀 이따 다시 읽을 확률이 높은 것을 뜻하고 공간적 지역성이란 지금 우리가 읽고 있는 게 100번지라면 다음에도 100번지 부근을 읽을 확률이 높은 것을 뜻한다. 이러한 지역성의 원리 그리고 더 빠른 디스크를 사용함으로써 demand paging을 사용하며 메모리를 아끼더라도 소요 시간 측면에서 큰 손해를 입지는 않는다.
페이지 교체(page replacement)
디멘딩 페이지 방식을 채택하더라도 언젠가 메모리가 꽉 찰 것이다. 그러면 새 페이지를 불러오기 위해 메모리에 적재되어 있는 많은 페이지 중 어느 페이지를 backing store로 몰아내야(page-out) 할 텐데 어느 페이지를 몰아내야 할까. 만약 page가 수정되지 않았다면 다음에 다시 불러들일 때 그냥 backing store에 있는 page를 그대로 불러오면 될 것이다.(수정되지 않았다면 그냥 하드디스크에 있는 그대로에서 안 변한 거니까 굳이 새로 저장할 필요 없음) 하지만 수정되었다면 수정된 것을 새로이 backing store에 저장해야 하므로 기왕이면 변경되지 않은 것들 중에서 victim page(쫓아낼 페이지)를 고르는 것이 좋다. 이를 위해 page table에 modified bit(=dirty bit)가 있다. 이 modified bit가 1이면 수정되었다는 뜻이고 0이면 수정되지 않았다는 뜻이다. 만약 모든 페이지가 수정되지 않은 page라면 혹은 둘 이상의 페이지가 수정되었다면 그들 중 어느 페이지를 victim page로 선택해야 할까. 이러한 victim page를 정하는 알고리즘을 page replacement algorithm이라 한다. 정리하자면 page replacement란 page를 적재할 수 있는 공간이 메모리에 없을 때 victim page를 선택해 그 페이지를 쫓아내고 그 자리에 새 페이지를 올리는 것을 뜻한다. 이때 어떤 page를 쫓을 것인지 정하는 알고리즘을 page replacement algorithm이라 부른다.
** 페이지 교체 알고리즘을 알아보기 전에 page reference string을 알아보자.
페이지 리퍼런스 스트링이란 페이지 폴트가 일어날 수 있는 문자들을 순서대로 적은 것을 뜻한다. 예를 들어, CPU가 요청하는 페이지가 순서대로 (1, 1, 1, 4, 6, 1, 1, 6, 6)이라면 page reference string을 구하는 과정은 다음과 같다. 맨 처음 1 page가 없으므로 첫 번째에서 page fault가 발생(1). 그 뒤 4와 6도 page fault 발생(1, 4, 6)한다. 그 뒤에 있는 (1, 1, 6, 6)에서의 제일 첫 번째 1은 메모리에 1 page가 있을 수도 없을 수도 있으므로 page reference string에 추가로 적는다.(1, 4, 6, 1) 마찬가지로 6도 page reference string에 추가로 적는다. (1, 4, 6, 1, 6) 최종적으로 page reference string는 (1, 4, 6, 1, 6)이다.
페이지 교체 알고리즘 (page replacement algorithm)
여러 페이지 교체 알고리즘이 있지만 우리는 FIFO(First-In First-Out), OPT(optimal), LRU(Least-Recently-Used) 세 가지에 대해 알아볼 것이다.
FIFO
- 먼저 적재된 페이지를 먼저 내쫓는 아주 간단한 알고리즘이다.
- 초기화 코드는 제일 처음 실행되며 그 뒤에는 사용되지 않으므로 제일 먼저 들어온 초기화 코드를 제일 먼저 내쫓는다면 페이지 교체 알고리즘의 효율이 좋지 않을까? 하는 생각으로부터 출발한 알고리즘이다.
- 예제:
- 페이지 참조열 = [7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1]
- # of frames = 3 (메모리에 올릴 수 있는 최대 page 수가 3개라는 것)
- 15 page faults
- 과정을 말로 하자면 맨 처음 7, 0, 1이 page fault 발생. 그다음 2를 올려야 하는데 FIFO니까 제일 먼저 들어온 7을 내쫓고 그 자리에 2를 넣음. 0은 memory에 있으니 넘어가고 3은 현재 메모리에 있는 page 중 제일 먼저 들어온 0을 쫓아내고 그 자리에 들어감... 이걸 반복하면 총 15번의 page fault가 발생한다.
- Belady's Anomaly
- 프레임 수(= 메모리 용량)가 증가하면 당연히 page fult가 줄어들어야 하는데 이상하게 프레임 수가 늘어나는 데도 불구하고 page fault 횟수가 증가하는 구간이 존재함.
- 무조건 그러는 것은 아니고 특정한 page 참조 열을 사용할 시 이런 현상이 일어난다. FIFO의 단점이다.

OPT
- 앞으로 가장 오랫동안 사용되지 않을 page를 victim으로 설정하자!
- 예제:
- 페이지 참조열 = [7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1]
- # of frames = 3
- 9 page faults
- 과정을 말로 하자면 맨 처음 7, 0, 1이 page fault 발생. 그다음 2를 올려야 하는데 현재 메모리에 올라가 있는 7, 0, 1 중 제일 오랫동안 사용되지 않을 것은 7이므로 7을 쫓아내고 그 자리에 2가 들어감. 그다음 0은 이미 메모리에 있으므로 page fault가 발생하지 않고, 그다음 3이 들어가야 하는데 현재 2, 0, 1 중 가장 오랫동안 사용되지 않을 것은 1이므로 1을 쫓아내고 그 자리에 3이 들어간다... 이것을 반복하면 총 9번의 page fault가 발생한다.
- 하지만 이 방법은 비현실적이다. 미래는 아무도 알 수 없기 때문이다. 나도 내가 컴퓨터를 사용할 때 뭘 먼저 사용하고 뭘 나중에 사용할지 모르는데 어떻게 남이 내 미래를 예언해서 알고리즘으로 만들 수 있겠는가...
LRU
- 앞으로의 미래는 모르지만 이전의 사용 내역은 아니까 메모리에 있는 페이지 중 가장 오랫동안 사용되지 않은 페이지를 먼저 내쫓는 방식이다.
- 최근에 사용되지 않은 페이지는 나중에도 사용되지 않을 거라는 아이디어로부터 출발한 알고리즘이다. 이것은 마치 최근 시험에서 높은 점수를 받은 학생이 그다음 시험에서도 높은 점수를 받을 거라고 생각하는 것과 비슷하다.
- 예제:
- 페이지 참조열 = [7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1]
- # of frames = 3
- 12 page faults
- 과정을 말로 하자면 맨 처음 7, 0, 1이 page fault 발생. 그 다음 2를 올려야 하는데 현재 메모리에 올라가 있는 7, 0, 1 중 제일 오랫동안 사용되지 않은 페이지인 7을 쫓아내고 그 자리에 2가 들어감. 그 다음 0은 이미 있으니까 패스하고, 3은 현재 메모리에 올라가 있는 2, 0, 1 중 가장 오랫동안 사용되지 않은 0을 내쫓고 그 자리에 들어감... 이것을 반복하면 총 12번의 page fault가 발생한다.
** global replacement vs local replacement
global replacement는 메모리 상의 모든 프로세스의 페이지에 대해 교체를 심의하는 방법이고, local replacement는 메모리 상의 자기 프로세스의 페이지에 대해 교체를 심의하는 방법이다.
쓰레싱(thrasing)
메모리에 올라온 프로세스의 개수가 증가하면 당연히 CPU 이용률이 증가할 것 같은데, 메모리에 올라와있는 프로세스의 개수가 일정 범위를 넘어서면 오히려 CPU 이용률이 감소하는 것을 쓰레싱이라 말한다. 쓰레싱이 발생하는 이유는 너무 많은 프로세스에 비해 적은 메모리 용량 때문에 생기는 빈번한 Page In/Out 때문이다. 빈번한 Page In/Out이 발생하면 hdd 읽기/쓰기가 빈번하게 발생한다는 것이고 I/O 시간이 늘어나면 그만큼 CPU 이용률이 내려가므로 CPU 이용률이 감소하는 것이다. 쓰레싱 극복을 위해 global replacement보다 local replacement가 더 나은 데 그 이유는 GR에서는 내가 쫓아낸 다른 프로세스의 page가 해당 process 실행 시 필요한 page 일수도 있기 때문이다. 최소한 내 process의 page를 out 시키면 내 차례가 다시 오기 전까지는 그 page를 In하진 않아도 되므로 GR보다 LR이 쓰레싱 극복에 도움이 된다.

쓰레싱 극복을 하기 위한 적절한 frame 할당은 어떤 식으로 하면 될까. 우선 프로세스에서 frame을 할당해 주는 것은 크게 정적 할당과 동적 할당으로 나뉜다. 아래를 참고하자.

균등 할당
- 예시
- # of frames = 99개
- # of process = 3개
- => 각 process 당 33개의 frame을 할당한다.
- 딱 봐도 비효율적이다. 많은 frame을 요구하는 프로세스도 있을 것이고 적은 frame을 요구하는 프로세스도 있을 것이다. 예를 들어, 메모장과 워드 프로세서에게 같은 frame을 할당하는 것을 생각해 보자.
비례 할당
- 정적으로 할당하긴 하는데 가중치를 줘서 무거운 process는 더 많이 할당하고 가벼운 프로세스는 더 적게 할당받도록 한다.
- 무거운 process라도 할당받은 것을 항상 다 쓰지는 않을 것이다. 좀 더 동적으로 할당받았으면 좋겠다.
working set model
- 이전 시간에 사용한 page들을 참고하여 이번 시간에 어느 정도의 frame이 필요할지 예측하는 것이다. 이를테면, 3초 전에 1, 6, 7 page를 사용했고, 2초 전에 2, 3, 6 page를 사용했고, 1초 전에 1, 3, 5 page를 사용했다면 이번에도 3개의 page를 사용할 것이라고 예측하여 3개의 frame을 할당해 주는 것이다. 몇 초 전까지의 정보까지를 확인하여 예측할 것인가에 대한 크기를 working set window라 부르며 working set window 범위의 시간을 근거로 계산하여 할당해 주는 frame을 working set이라고 부르고 각 시간대마다 응집되어 있는 page들을 locality라 부른다.

page-fault frequency(PFF)
- page fault 발생 비율의 상한/하한선을 정해 놓고 page fault 상한선 초과 process에 더 많은 frame을 할당하고 하한선 이하 process의 frame은 회수하는 방식이다.
- page fault가 page fault 상한선을 초과하여 발생하면 frame을 더 할당하여 page fault가 덜 일어나도록 하고, page fault가 하한선 미만으로 내려가면 frame을 너무 많이 가지고 있는 것으로 판단하여 frame을 회수하는 것이다.

페이지 크기
페이지의 크기는 메모리 양의 증가에 따라 점차 커지는 경향이 있으며 일반적으로 4KB ~> 4MB로 증가하였다. 페이지 크기가 끼치는 영향은 내부 단편화 확률, page-in/out 시간, page table 크기, memory resolution, page fault 발생 확률 등이 있다.
내부 단편화 확률
- page size가 커질수록 내부 단편화 확률 증가
page-in/out 시간
- page size가 커질수록 In/Out 시간 감소
- page size가 커지면 정보를 한 번에 많이 올리니까 page-in/out이 잘 발생하지 않음
page table 크기
- page size가 커질수록 page table 크기 감소
- 잘게 자를수록 row가 많아질 텐데 큼직하게 나누니까 저장할 row가 몇 개 안 되므로 page table 크기 감소
memory resolution(메모리 해상도)
- page size가 커질수록 memory resolution 감소
- memory resolution이란 내가 원하는 정보들만 딱 메모리에 있을 확률을 뜻하는데 page size가 커질수록 내가 원하지 않는 것들도 함께 적재될 확률이 높아지니까 memory resolution 감소
page fault 발생 확률
- page size가 커질수록 page fault 발생 확률 감소
- page size가 커질수록 많이 가져오니까 원하는 정보가 있을 확률이 올라가므로 page fault 발생 확률은 내려감
** 페이지 테이블의 기술 동향
원래는 별도의 chip(TLB 캐시)으로 존재했지만 기술의 발달에 따라 캐시 메모리처럼 CPU 안으로 들어가게 되었다.(on-chip)
https://sunday5214.tistory.com/6
운영체제 정리 2. 쓰레드
프로세스와 쓰레드의 차이 -자원의 소유권 특성 : 프로세스는 자신의 이미지를 위한 가상주소 공간을 포함, (프로세스 이미지란 프로세스 제어블록에 정의된 프로그램과 데이터, 스택, 속성, 들
sunday5214.tistory.com
'운영체제' 카테고리의 다른 글
| 프로세스와 스레드 (0) | 2023.07.03 |
|---|---|
| 운영체제 기본 마지막 - 파일 시스템 (0) | 2023.01.26 |
| 운영체제 기본 9 - 프로세스 동기화 (0) | 2023.01.23 |
| 운영체제 기본 8 - 프로세스 생성과 종료 (0) | 2023.01.23 |
| 운영체제 기본 6 - 프로세스 관리 (0) | 2023.01.19 |