http://www.kocw.net/home/search/kemView.do?kemId=978503
운영체제
운영체제의 정의 및 역할 등에 대해 알아보고, 운영체제의 주요 요소들, 즉 프로세스 관리, 주기억장치 관리, 파일 시스템 등에 대해 공부한다.
www.kocw.net
파일 시스템(File system)
이전까지 OS의 역할 중 process management(CPU scheduling, process synchronization)와 memory management(paging, virtual memory)에 대해 배웠다. 이번에는 file system에 대해 배워보자. 파일 시스템은 보조기억 장치에 관한 관리를 맡는 부서이다. file system의 전부를 배울 건 아니고, file system의 file allocation(파일 할당)에 대해서 배울 것이다.
** 하드디스크는 아래 그림과 같이 이루어져 있으며 데이터를 기입할 때는 코일에 전기 신호를 줘서 track의 sector에 N, S극을 저장하고 읽을 때에는 판을 회전시켜 N극 혹은 S극이 coil 밑을 지날 때 coil에 전기 신호를 일으키는 방식으로 읽는다. 이때 sector 들의 집합을 block이라 하며 하드디스크는 이 block 단위로 읽기/쓰기를 한다. 그래서 하드디스크를 block device라고도 한다. 참고로 block device의 반대는 character device이며 keyboard가 이에 해당된다.(글자 단위로 읽기/쓰기) 어쨌든 블록 디바이스인 하드디스크는 우리가 메모장에 'a'라는 단 한 글자를 적고 저장을 하더라도 한 블록 단위로 저장을 하기 때문에 1byte가 아닌 4byte로 저장이 된다. 이 블록의 크기가 크면 header를 조금 움직여도 한 번에 많이 읽어오니까 속도가 빠르지만 위 예시처럼 용량 낭비가 일어날 수 있고 반대로 블록 크기를 작게 설정하면 용량 낭비는 적지만 같은 양을 읽더라도 header를 자주 움직여야 하니까 속도가 느리다.(tradeoff가 있음)
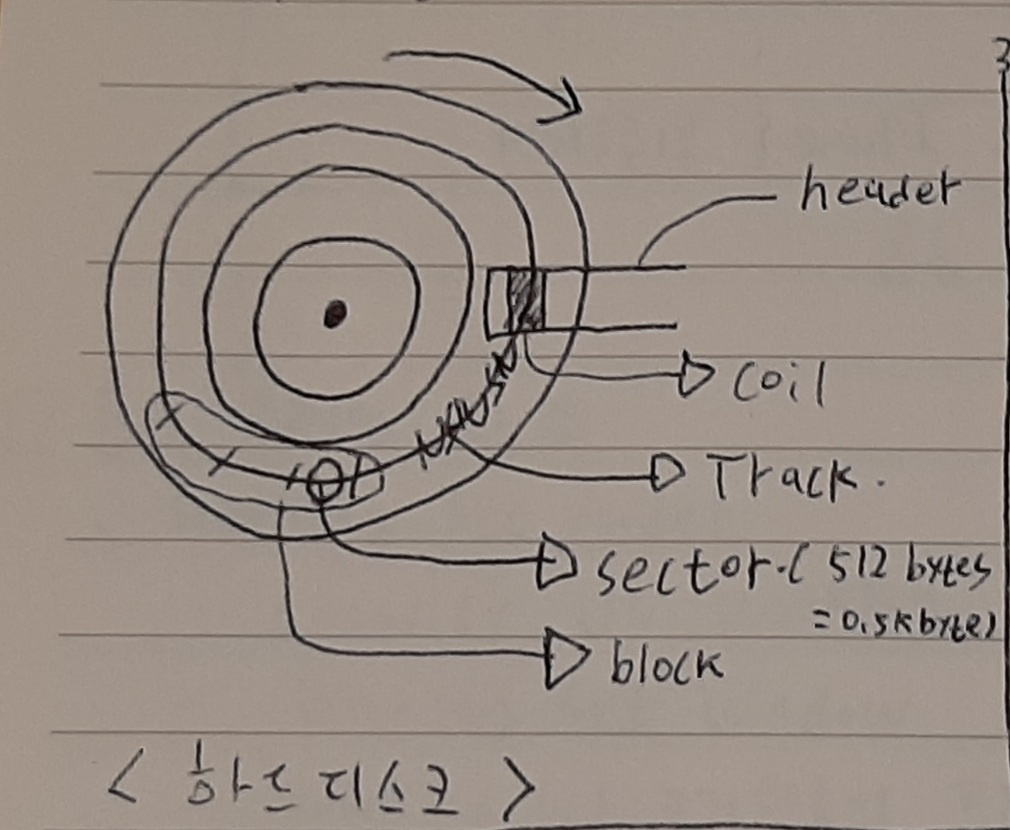
파일 할당(File allocation)
하드 디스크를 논리적으로 그리면 아래 그림과 같다. 하드 디스크는 여러 free block(빈 공간)을 갖고 있는데 파일에 어느 free block을 할당하여 저장할 것인가를 정하는 것이 파일 할당이다. 파일 할당의 종류로는 연속 할당(contiguius allocation), 연결 할당(linked allocation), 색인 할당(index allocation)이 있다.

Contiguous allocation(연속 할당)
- 각 파일에 대해 디스크 상의 연속된 블록을 할당하는 방법이다. 디스크 헤더의 이동이 최소화되기 때문에 빠른 I/O 성능을 기대할 수 있다. 예전 IBM VM/CMS에서 사용되었다. 동영상, 음악 vod 등 연속된 정보를 저장하는데 적합하며 순서대로 읽을 수도 있고(sequential access, 순차 접근) 특정 부분을 바로 읽을 수도 있다. (direct access, 직접 접근) 파일이 삭제되면 hole이 생성되므로 파일의 생성과 삭제가 계속될수록 곳곳에 hole들이 흩어진다. 따라서 외부 단편화 문제가 발생하여 디스크 공간 낭비를 부른다. 게다가 파일 크기가 계속 증가한다면 기존의 hole 배치로는 저장이 불가능한 상황이 올 수도 있다.
** file에 대한 정보를 모아둔 곳을 디렉터리(Directory)라 한다. 디렉터리는 file에 대한 정보를 테이블로 모아둔다. 예를 들어 f1이라는 파일에 대한 디렉터리는 아래와 같다. 아래 상황에서 f1의 시작 블록이 0이니까 f1의 두 번째 블록은 1에 있다고 예측할 수 있다. 따라서 내가 읽고 싶은 부분을 바로 읽을 수 있는 것이다.
Linked allocation(연결 할당)
- linked list랑 비슷하다 파일 디렉터리는 제일 처음 블록을 가리키며 block의 제일 마지막에는 다음 블록이 어디에 위치해 있는지 적혀 있다. 따라서 각 블록은 포인터 저장을 위한 4 bytes 정도의 공간이 필요하다. 예를 들어 새로운 파일을 만든다면 비어있는 임의의 블록을 첫 블록으로 할당하고 파일이 커져 다른 블록이 필요하면 다른 블록을 할당받고 첫 블록의 포인터에 다음 블록의 주소를 저장하는 방식이다. 연결 할당 방식을 사용하면 외부 단편화 문제가 해결된다. 하지만 단점으로 순서대로 읽기는 가능하지만 직접 접근이 불가능하고, 포인터를 위해 블록 당 4 bytes 정도의 손실이 있으며 포인터가 손상되면 그다음 정보들을 전부 접근할 수 없고, 헤더가 빈번히 움직여야 하므로 속도가 느리다는 단점이 있다.
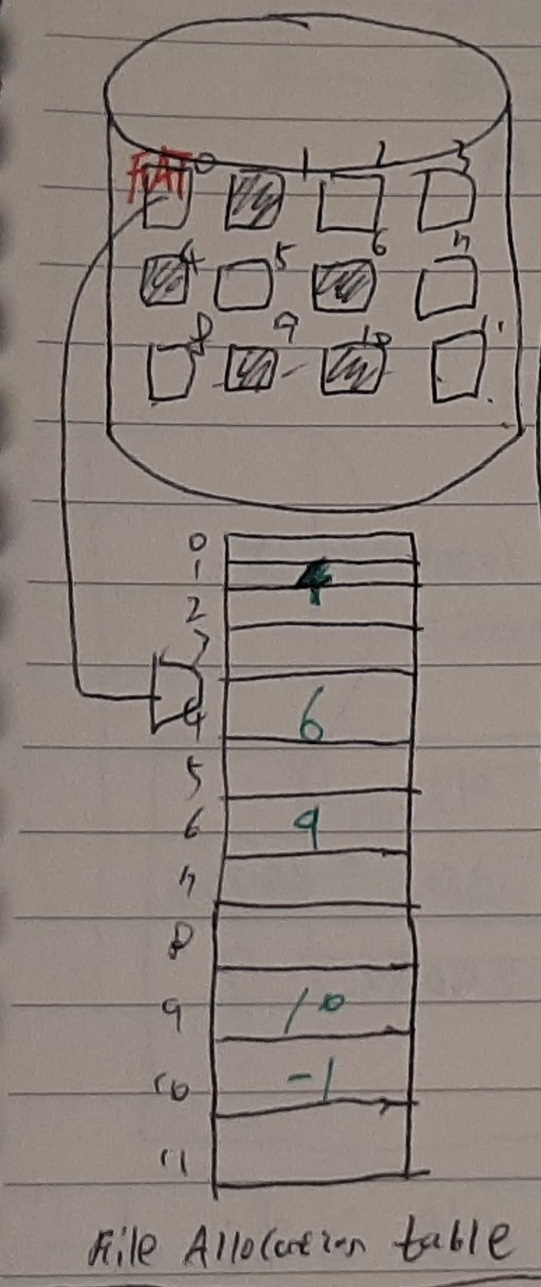
- 연결 할당의 개선 방식으로 FAT(File Allocation Table System) 파일 시스템이 있다. FAT는 USB에 많이 사용되는 방식이며 포인터를 각 블록의 마지막에 저장하는 것이 하나의 table을 만들어 거기에 모든 포인터를 저장하는 방식이다. 이 방식을 사용하면 순차 접근은 물론이고 직접 접근도 가능해진다.
- 5kb의 file을 기본적인 Linked allocation을 사용하여 저장하면 각 block에 다음 block을 가리키는 포인터들이 존재해야 한다. 이러면 direct access가 불가능해진다. 각 블록의 pointer를 순차적으로 header가 읽어야 하기 때문이다. 또 pinter가 읽을 수 없게 되면(Bad sector) 그 이후의 모든 정보를 읽을 수 없게 된다.

- 5kb의 file을 FAT를 사용하여 저장하면 아래와 같은 그림이 된다. 각 블락에 포인터를 만들지 않아도 file allocation table에 해당 정보가 적혀있으므로 문제없이 작동한다. 각 블록들을 순차적으로 읽지 않고 FAT만 보고 바로 원하는 블록으로 이동할 수 있으므로 direct access가 가능해진다.(테이블은 메모리에 올라가 있을 테니 헤더가 직접 움직이는 Linked allocation과는 다르다.) 또, 일부 sector가 Bad sector가 되더라도 FAT만 잘 살아있다면 문제없이 다음 sector를 지정할 수 있다. 물론 FAT이 날라가면 이런 작동이 불가능하므로 이중 저장(백업)을 한다. FAT16의 경우 2^16개의 포인터를 저장할 수 있고 FAT32의 경우 2^32개의 포인터를 저장할 수 있다.
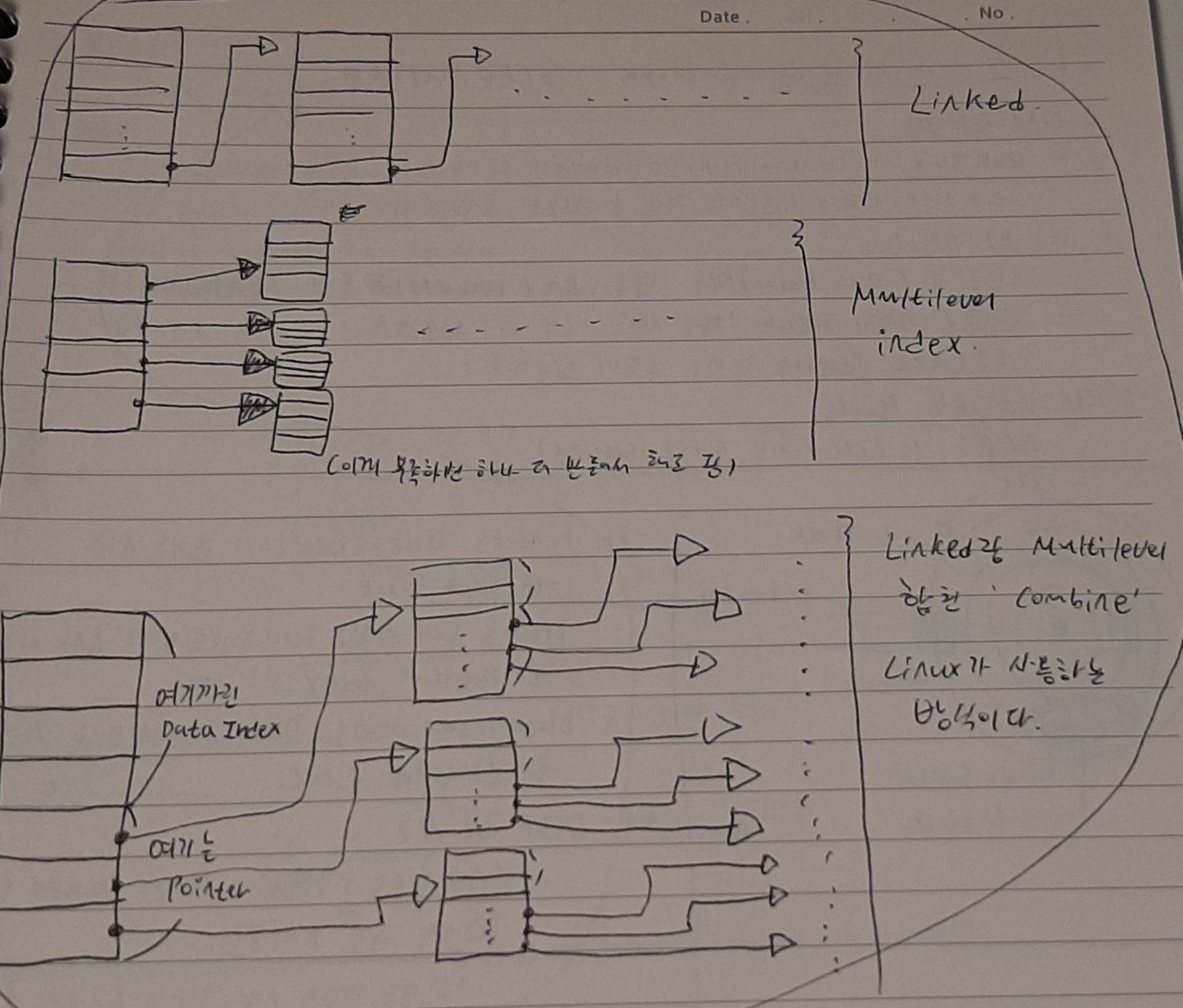
Indexed allocation(색인 할당)
- 파일 하나당 한 개의 인덱스 블록을 갖는다. 인덱스 블록은 포인터의 모음이다. 쉽게 말해 파일 하나당 하나의 file allocation table을 갖는 것이다. Directory는 Index block을 가리키며 Unix/Linux에서 사용되는 방법이다. 장점으로는 순차 접근은 물론 직접 접근도 가능하며 외부 단편화가 없다는 장점이 있고, 단점으로는 인덱스 블록 할당에 따른 저장 공간 손실이 있다는 것이다. 예를 들어 1byte짜리 파일을 저장하기 위해 Data 1블록 + Index 1 블록이 필요한 것이다. 다시 말해, 내부 단편화가 심하다. 그리고 파일의 최대 크기가 제한된다. 이게 무슨 말이냐면 예를 들어 1블록의 크기가 512 byte일 때 4 * 128 = 512이므로 하나의 블록에는 총 128개의 인덱스만 저장할 수 있다. 따라서 그것을 초과하는 크기를 갖는 파일은 저장하지 못한다.
- Linked, multilevel index, combined 등을 사용하여 위 파일의 최대 크기 제한 문제를 해결할 수 있다.
- Linked는 인덱스 블록의 마지막에 다음 인덱스 블록의 주소를 넣는 것이다.
- multilevel index는 각 인덱스 블록이 다른 인덱스 블록을 가리킬 수 있도록 하는 방법이다.
- combined는 이름에서 알 수 있듯 Linked와 multilevel index를 합친 방법이다. Linux가 해당 방식을 사용한다.

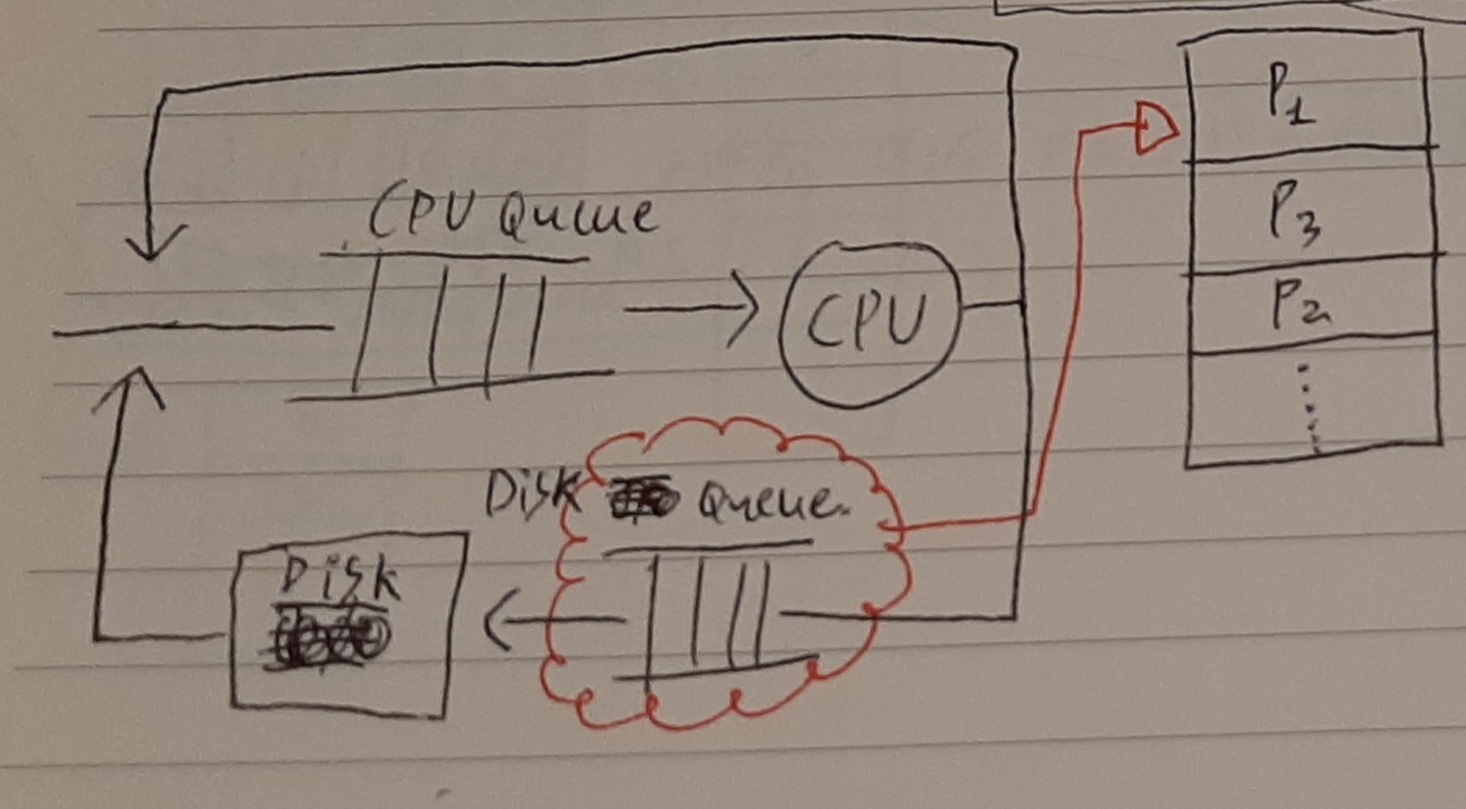
디스크 스케줄링(Disk scheduling)
디스크 접근 시간은 seek time, rotation delay, transfer time의 합이다. header를 원하는 트랙까지 옮기는 시간이 seek time, 트랙을 돌려 원하는 block을 coil 아래로 옮기는 시간이 rotation delay, block이 coil 아래를 지나며 전기 신호를 만드는 시간이 transfer time이다. 이중 seek time(탐색 시간)이 가장 큰 비중을 차지한다. 다중 프로그래밍 환경에서 디스크 큐에는 많은 요청들이 쌓여있다. 요청들을 어떻게 처리하면 seek time을 줄일 수 있을까. 다시 말해, 효율적으로 탐색하여 seek time을 최대한 줄이는 효율적인 스케줄링 방법은 무엇이 있을까를 정하는 것이 디스크 스케줄링이다. 디스크 스케줄링 방법의 종류에는 FCFS(First-Come First-Served), SSTF(Shortest-Seek-Time-First), Scan이 있다.

FCFS(First-Come First-Served)
- 가장 쉬운 방법으로 그냥 먼저 온 놈 먼저 처리하는 방법이다.
- 예제
- 200 cylinder disk, 0... 199
- Disk queue: 98, 183, 37, 122, 14, 124, 65, 67
- Head is currently at cylinder 53
- Total head movement = 640 cylinders
- 아래 사진을 보면 header의 이동 경로를 파악할 수 있다. (98-53) + (183-98) + (183-37) + (122-37) + (122-14) + (124-14) + (124-65) + (67-65) = 640
- 예제를 보면 알 수 있듯 매우 비효율적이다.

SSTF(Shortest Seek Time First)
- 현재 헤더로부터 가장 가까운 요청 먼저 처리하는 방법이다.
- 예제
- 200 cylinder disk, 0... 199
- Disk queue: 98, 183, 37, 122, 14, 124, 65, 67
- Head is currently at cylinder 53
- Total head movement = 236 cylinders
- 헤더의 이동 경로를 생각해 보자면 헤더와 가장 가까운 요청 순서로 움직이므로 53 > 65 > 67 > 37 > 14 > 98 > 122 > 124 > 183이다. 따라서 이동량은 12 + 2 + 30 + 23 + 84 + 24 + 2 + 59 = 236이다.
- 문제점으로 starvation이 있다. 헤더로부터 멀리 떨어져 있으면 운나쁘면 영원히 읽히지 않을 수도 있다. 그리고 SSTF는 optimal 한 방법이 아니다.
Scan Disk
- head를 안쪽으로 끝까지 넣었다가 뒤쪽으로 끝까지 빼는 동작을 반복하는 것
- 예제
- 200 cylinder disk, 0... 199
- Disk queue: 98, 183, 37, 122, 14, 124, 65, 67
- Head is currently at cylinder 53
- Total head movement = 53 + 183 = 236 cylinders
- 아래 사진을 보면 헤더가 0으로 쭉 움직였다가 다시 183으로 쭉 움직인다. 따라서 헤더는 53 + 183 = 236 만큼 움직인다.

** 생각해 보기
실린더에 대한 요청은 균일한 분포를 갖는다. 요청은 실린더 안쪽에만 몰려있는 것도 아니고 바깥쪽에만 몰려있는 것도 아니다. 마치 눈이 내리면 운동장에 고루 눈이 쌓이는 것처럼 요청은 실린더 전체에 고루 분포된다. 따라서 53에서 0 방향으로 스캔을 한 다음 0에서 199 방향으로 다시 스캔하는 것보다 53에서 0 방향으로 스캔을 하고 199까지 스캔 없이 그냥 이동한 다음 0 방향으로 스캔하는 것이 더 효율적이다. 이렇게 스캔하면 시작(53)과 끝(53)이 같으므로 이러한 방식의 scan을 circular scan(C-scan)이라 한다.

** Scan의 변종
c-scan
- 시작 실린더 위치와 최종 실린더 위치가 같은 circular scan
Look
- 헤드는 각 방향으로 최종 요청까지만 이동함. 예를 들어 위 예시에서 53에서 시작하면 0까지 가는 게 아니라 14까지만 가고 199까지 가는 게 아니라 183까지만 가는 것.
- 어느 방향으로 가기 전에 그 방향의 request가 있는지 없는지 미리 보기(look)때문에 Look이라 한다.
c-look
- Look에 c-scan을 합한 것
** Elevator algorithm
- scan, c-scan, look, c-look의 이동 경로를 세로로 세우면 엘리베이터처럼 쭉 내려갔다가 쭉 올라갔다가 하는 모양을 띤다. 그래서 scan의 또 다른 이름이 elevator algorithm이다.

'운영체제' 카테고리의 다른 글
| 프로세스와 스레드 (0) | 2023.07.03 |
|---|---|
| 운영체제 기본 10 - 주기억장치 관리 (0) | 2023.01.26 |
| 운영체제 기본 9 - 프로세스 동기화 (0) | 2023.01.23 |
| 운영체제 기본 8 - 프로세스 생성과 종료 (0) | 2023.01.23 |
| 운영체제 기본 6 - 프로세스 관리 (0) | 2023.01.19 |